Clusters
Riak’s default mode of operation is to work as a cluster consisting of multiple nodes, i.e. multiple well-connected data hosts.
Each host in the cluster runs a single instance of Riak, referred to as a Riak node. Each Riak node manages a set of virtual nodes, or vnodes, that are responsible for storing a separate portion of the keys stored in the cluster.
In contrast to some high-availability systems, Riak nodes are not clones of one another, and they do not all participate in fulfilling every request. Instead, you can configure, at runtime or at request time, the number of nodes on which data is to be replicated, as well as when replication occurs and which merge strategy and failure model are to be followed.
The Ring
Though much of this section is discussed in our annotated discussion of the Amazon Dynamo paper, it nonetheless provides a summary of how Riak implements the distribution of data throughout a cluster.
Any client interface to Riak interacts with objects in terms of the bucket and key in which a value is stored, as well as the bucket type that is used to set the bucket’s properties.
Internally, Riak computes a 160-bit binary hash of each bucket/key pair and maps this value to a position on an ordered ring of all such values. This ring is divided into partitions, with each Riak vnode responsible for one of these partitions (we say that each vnode claims that partition).
Below is a visual representation of a Riak ring:
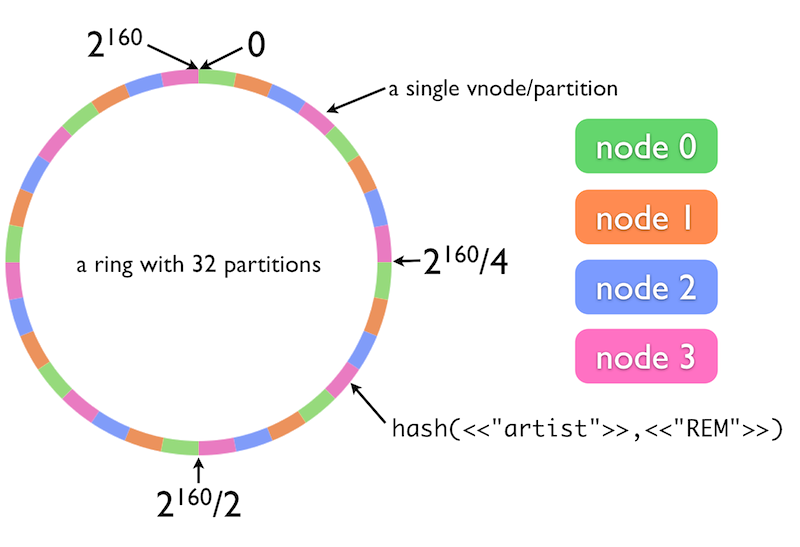
The nodes of a Riak cluster each attempt to run a roughly equal number of vnodes at any given time. In the general case, this means that each node in the cluster is responsible for 1/(number of nodes) of the ring, or (number of partitions)/(number of nodes) vnodes.
If two nodes define a 16-partition cluster, for example, then each node will run 8 vnodes. Nodes attempt to claim their partitions at intervals around the ring such that there is an even distribution amongst the member nodes and that no node is responsible for more than one replica of a key.
Intelligent Replication
When an object is being stored in the cluster, any node may participate as the coordinating node for the request. The coordinating node consults the ring state to determine which vnode owns the partition in which the value’s key belongs, then sends the write request to that vnode as well as to the vnodes responsible for the next N-1 partitions in the ring (where N is a configurable parameter that describes how many copies of the value to store). The write request may also specify that at least W (=< N) of those vnodes reply with success, and that DW (=< W) reply with success only after durably storing the value.
A read, or GET, request operates similarly, sending requests to the vnode that “claims” the partition in which the key resides, as well as to the next N-1 partitions. The request also specifies R (=< N), the number of vnodes that must reply before a response is returned.
Here is an illustration of this process:
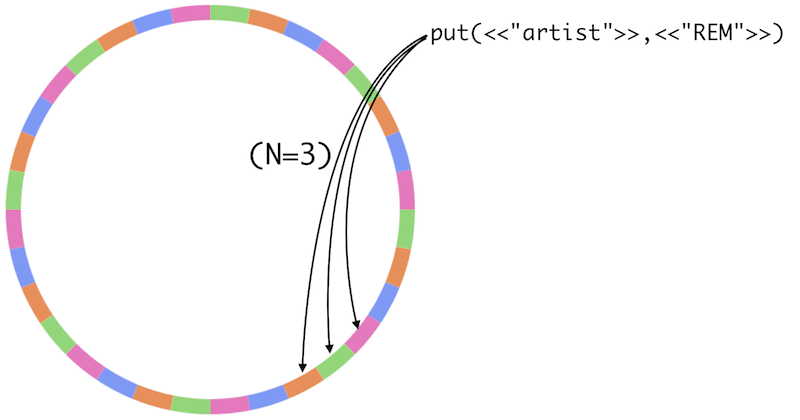
When N is set to 3, the value REM is stored in the key artist. That
key is assigned to 3 partitions out of 32 available partitions. When a
read request is made to Riak, the ring state will be used to determine
which partitions are responsible. From there, a variety of
configurable parameters determine how Riak
will behave in case the value is not immediately found.
Gossiping
The ring state is shared around the cluster by means of a “gossip protocol.” Whenever a node changes its claim on the ring, it announces, i.e. “gossips,” this change to other nodes so that the other nodes can respond appropriately. Nodes also periodically re-announce what they know about ring in case any nodes happened to miss previous updates.