V3 Multi-Datacenter Replication Reference:
Architecture
How Version 3 Replication Works
In Multi-Datacenter (MDC) Replication, a cluster can act as either the
- source cluster, which sends replication data to one or
- sink clusters, which are generally located in datacenters in other regions or countries.
Bidirectional replication can easily be established by making a cluster both a source and sink to other clusters. Riak Enterprise Multi-Datacenter Replication is considered “masterless” in that all clusters participating will resolve replicated writes via the normal resolution methods available in Riak.
In Multi-Datacenter Replication, there are two primary modes of operation:
- Fullsync replication is a complete synchronization that occurs between source and sink cluster(s), which can be performed upon initial connection of a sink cluster if you wish
- Realtime replication is a continual, incremental synchronization triggered by successful writing of new updates on the source cluster
Fullsync and realtime replication modes are described in detail below.
Concepts
Sources
A source refers to a cluster that is the primary producer of replication data. A source can also refer to any node that is part of the source cluster. Source clusters push data to sink clusters.
Sinks
A sink refers to a cluster that is the primary consumer of replication data. A sink can also refer to any node that is part of the sink cluster. Sink clusters receive data from source clusters.
Cluster Manager
The cluster manager is a Riak Enterprise service that provides
information regarding nodes and protocols supported by the sink and
source clusters. This information is primarily consumed by the
riak-repl connect command.
Fullsync Coordinator
In fullsync replication, a node on the source cluster is elected to be the fullsync coordinator. This node is responsible for starting and stopping replication to the sink cluster. It also communicates with the sink cluster to exchange key lists and ultimately transfer data across a TCP connection. If a fullsync coordinator is terminated as the result of an error, it will automatically restart on the current node. If the node becomes unresponsive, a leader election will take place within 5 seconds to select a new node from the cluster to become the coordinator. In the event of a coordinator restart, a fullsync will have to restart.
Fullsync Replication
Fullsync replication scans through the list of partitions in a Riak cluster and determines which objects in the sink cluster need to be updated. A source partition is synchronized to a node on the sink cluster containing the current partition.
Realtime Replication
In realtime replication, a node in the source cluster will forward data to the sink cluster. A node in the source cluster does not necessarily connect to a node containing the same vnode on the sink cluster. This allows Riak to spread out realtime replication across the entire cluster, thus improving throughput and making replication more fault tolerant.
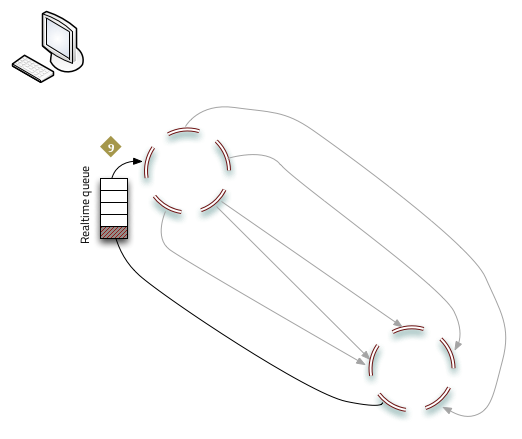
Initialization
Before a source cluster can begin pushing realtime updates to a sink, the following commands must be issued:
riak-repl realtime enable <sink_cluster>After this command, the realtime queues (one for each Riak node) are populated with updates to the source cluster, ready to be pushed to the sink.
riak-repl realtime start <sink_cluster>This instructs the Riak connection manager to contact the sink cluster.
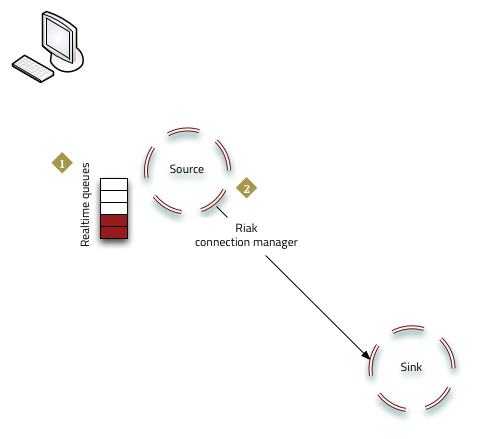
At this point realtime replication commences.
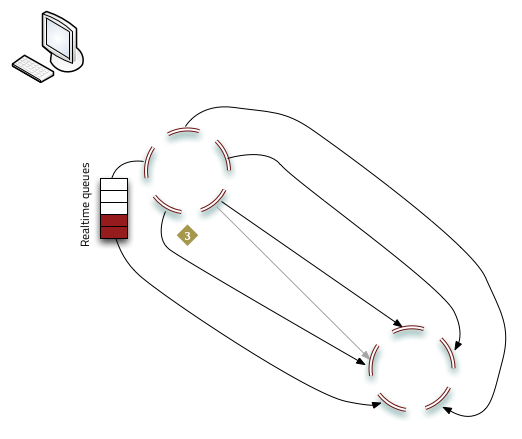
- Nodes with queued updates establish connections to the sink cluster and replication begins.
Realtime queueing and synchronization
Once initialized, realtime replication continues to use the queues to store data updates for synchronization.
- The client sends an object to store on the source cluster.
- Riak writes N replicas on the source cluster.
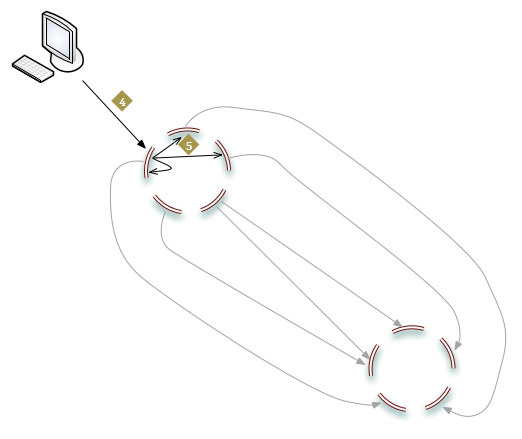
- The new object is stored in the realtime queue.
- The object is copied to the sink cluster.
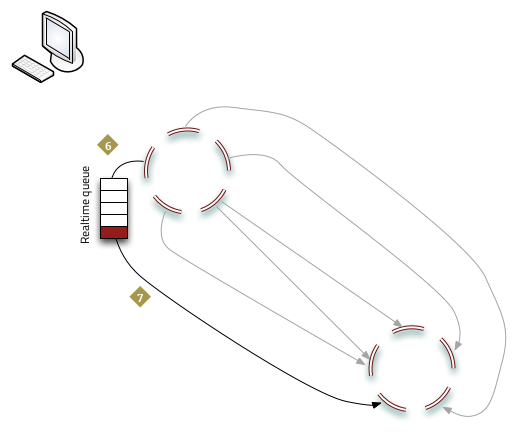
- The destination node on the sink cluster writes the object to N nodes.
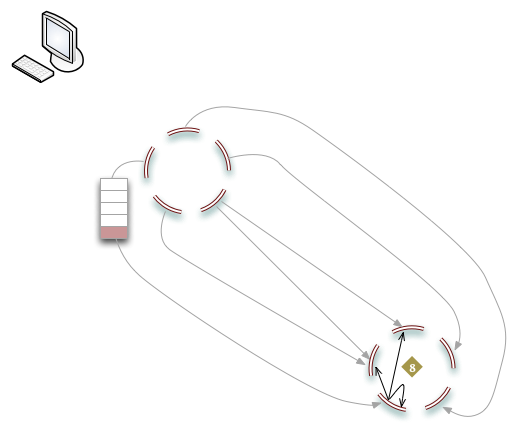
- The successful write of the object to the sink cluster is acknowledged and the object removed from the realtime queue.
Restrictions
It is important to note that both clusters must have certain attributes
in common for Multi-Datacenter Replication to work. If you are using
either fullsync or realtime replication, both clusters must have the
same ring size; if you are using fullsync
replication, every bucket’s n_val must be the same in both the
source and sink cluster.